IntoFocus: Anonymizing Images for Crowdsourcing
Team Members: Abdullah Alshaibani, Li-Hsin Tseng, Sylvia Carrell
Introduction and Related Work
With the rising use of human computation systems,
there is a real need for solving tasks, especially with images, while
preserving private and sensitive information in those tasks. Finding sensitive
information in images is a problem that cannot simply be solved by AI (figure
1). Even the automatic face and license plate
blurring algorithm used by Google in their Street View is not 100% accurate
[6]. However, such problems can be solved even when the image is heavily
redacted with the use of human computation and Amazon Mechanical Turk (AMT).
|
Figure 1:
Current technology on face detection is not mature enough to find all the
faces within one image (e.g. faces in profile or partially blocked faces). The blue box is generated by a python face detection API. |

The Pull the Plug paper by Gurari
et al. focuses on images in the
foreground, which is not always the case with personal information (faces,
account numbers, etc.). Our focus is highlighting any and all personal
information in an image before submitting it to AMT to get the task solved,
whether the information is in the foreground or background.
Relevant to our work is the VizWiz
paper by Bigham et
al. , which performs the task of helping blind and the visually impaired
by taking a picture and describing the task using a voice recording and posting
a Human Intelligence Task (HIT) to AMT. The workers would then answer the
question about the image. One concern that surfaces from this process is that
the visually impaired person might take a picture that contains sensitive
information, which they would not want a stranger to see, without even knowing.
IntoFocus introduces a solution: an earlier-stage
task process in order to cover the sensitive information, before that task is
submitted to workers.
Sorokin et
al. proposes a system that uses crowdsourcing to allow robots to grasp
unfamiliar objects. Their system allows the robot to take images of an object
and asks workers to draw a contour on the object so the robot would find the
object’s edges. The issue with this approach is the possibility of Personally
Identifiable Information (PII) being visible in the image that might expose
people that were not aware that the robot was taking images. Similar to VizWiz, their system would share PII without the users knowing about it.
Lasecki et al. showed that it is not safe
to trust some workers with any private/personal information, which would cause
issues for the previous projects. We aim to solve this gap with our presented
research.
Boult presented cryptographically invertible
obscurations among videos so that while preserving the privacy aspect in a
video, the general surveillance would not be compromised. In contrast, IntoFocus has crowd workers select the regions that they
believe contain PII. The images with the regions they select can be further
redacted into images that can be served as the same input for the surveillance
usage.
Closely related to IntoFocus
is
Lasecki et
al.’s research where they segment a single image into smaller segments
and ask the workers to highlight the segments that contain sensitive
information. The issue with their method is the loss of information when the
image is segmented. Because the workers do not see the full photo, they might
not be able to say that a specific region contains private information because
it is cut in half or is otherwise taken out of context.
The primary contributions of this paper are: (1) The introduction of IntoFocus, a framework for preserving privacy through a systematic process that starts with a heavily filtered image, and tasks the workers to redact sensitive regions before they are exposed to the underlying content, and (2) an evaluation of the process and its feasibility.
Research questions
●
Can we reliably redact personal information for the ultimate purpose
of analyzing the images without sharing
private information?
●
Is a 3 stage system enough to preserve the
privacy of the people in the image?
●
Is it feasible to trust a single worker to the
task of finding all the locations of sensitive information in a given stage?
●
What is the smallest face that can be detected by the crowd in this
framework?
Design and Process
Judging by the requirements to show that such an
algorithm works, we need to build a working framework that accepts an image and
returns a redacted image. The following is the process of operation of the
framework:
1.
Display the image with the highest level of median filter (applied
using the
Python Imaging Library) to a worker and ask them to highlight
(using bounding boxes) the locations of sensitive information. This will be
presented to n workers and all the
highlighted spaces will be obfuscated before the image is sent to the next step.
2.
The next steps are repeated i times, depending on the experiment cycle:
a.
The next image will have a lower blur value, and all the regions that
were previously highlighted will be obfuscated. The workers will be asked to
highlight the areas that contain sensitive information.
To accomplish the above framework, we first need
to find the optimal filter levels for each stage. Since we do not know the
amount of information (private or not) in the images being sent by the
requesters, the first stage needs to have a high radius filter value to the
point that not a lot of information can be seen in the image. If there is a
face in the entire image or there is a face covering half of the page with
people in the background that are further away (i.e. a selfie), we still need
to be able to redact that information without allowing the workers to extract
the information, such as the following images. To obtain such images, we used a
maximum radius of 41 pixels and a minimum radius of 13 pixels. To achieve that
we need to build a redaction platform that allows us to apply different filter
levels to specific spaces in an image.
|
Original image |
Stage 1 (41
pixel radius) |
Stage 2 (27
pixel radius) |
|
Stage 3 (21
pixel radius) |
Stage 4 (17
pixel radius) |
Stage 5 (13
pixel radius) |






Figure 2: The
level of blur goes down when the stage number goes up.
Implementation
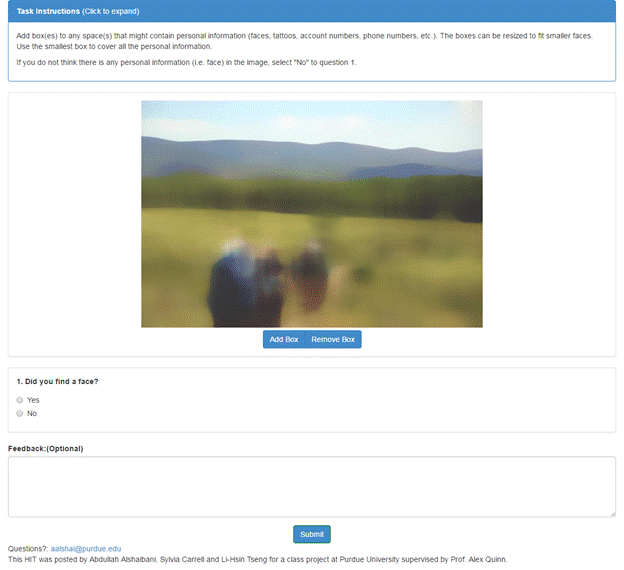
Figure 3 : Our task interface.
Our task interface is shown in figure 3. In it,
the workers are shown a blurred image and are instructed to add box(es) to the regions that they
believe might contain personal information. After that, they are asked to
answer a question on whether they have found a face within the image.
After three workers have completed adding box(es) onto the same image in the
same stage, the image is then redacted with the box(es)
and sent to the next stage for evaluation.
Recruiting
A total of 50 unique participants were recruited
through Amazon Mechanical Turk. These workers saw 75 total HITs. Each HIT paid
the worker $0.15. Workers were allowed a maximum of 5 minutes to complete each
task. Workers were restricted to working on images only within the same stage.
Six workers submitted their answers within 10 seconds of accepting the HIT.
Three workers took longer than 150 seconds to submit. The average time spent on
each HIT was around 51.2 seconds (for an average hourly rate of $19.59). The
median time spent working on the HIT was 42 seconds.
Evaluation
The framework was tested using one experiment.
This experiment contained all 5 stages shown above and had 3 workers for each
stage. Their results were aggregated (i.e. the union of the three submissions)
into a single image for the second stage and so on.
Though we had an error in our database insertion,
every worker's submission was correctly captured by AMT and thus is used in our
evaluation. Also, we had one worker email us about his confusion over the
wording of our task. Although we had some workers submit “questionable” data,
we still included every single submission in our results evaluation (we did not
reject any submissions).
The framework was tested with the help of the
CrowdLib API on AMT. All the task responses and
redactions are compared to the ground truth to ensure the crowd-redacted image
did not disclose personal information. The ground truth was obtained by the
researchers.
Results
|
Stage number |
The images that
is shown to the workers |
The images with
the drawn worker boxes |
|
1 |
|
|
|
2 |
|
|
|
3 |
|
|
|
4 |
|
|
|
5 |
|
|
|
Final image |
|
|










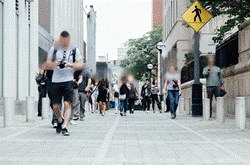

Figure 4: This
table shows the images being shown to the workers at different stages and the
boxes they found.
As you can see in figure 4 above, the image that is shown to the workers in each stage becomes incrementally less blurry. As the image becomes less blurry, more faces in total are being selected.
|
Original image |
Original image
with ground truth |
|
|
|


Figure 5: This table shows the original image and the ground truth.
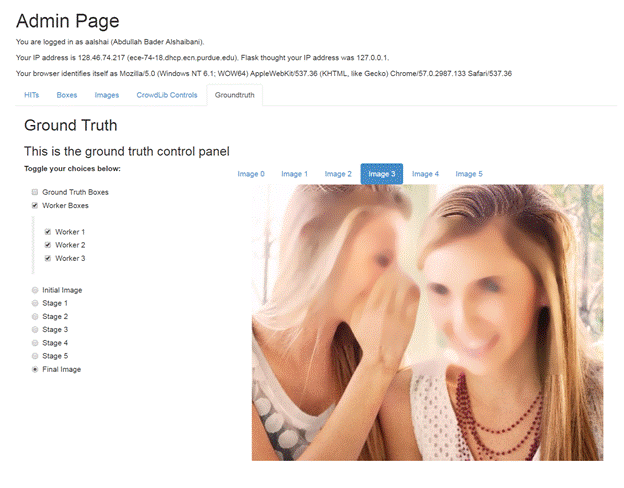
Figure 6: The results interface with the final redacted image 3
The result interface is shown in figure 6, where the person creating the HITs can see all the different stages for each of the images. It can also display the boxes that each of the workers added, as well as the ground truth. We can also see the content of the HITs results and post HITs on this interface. We also show all the information relating to all the images being posted, such as the number of worker attempts and the raw box data.
|
Original image |
Final image |
|
|
|


Figure 7: This table shows the initial and final stage of image 4.
In figure 7, you can see from the original image that it has no faces that needed to be selected for our task. However, after going through the process of blurring and selecting possible regions for faces, the workers in the initial stages (1, 2 and 3) selected those regions because they seemed like the front of human bodies, when in truth they were their backs, something the later workers realized and avoided.
|
|
image 1 |
image 2 |
image 3 |
image 4 |
image 5 |
|
Total number of
faces |
10 |
29 |
2 |
0 |
16 |
|
Number of faces
found |
8 |
6 |
2 |
0 |
9 |
|
Number of faces
not found |
2 |
23 |
0 |
0 |
7 |
|
Percentage of
faces not found (%) |
20 |
79.3 |
0 |
0 |
43.75 |
|
Percentage of
faces found (%) |
80 |
20.6 |
100 |
100 |
56.25 |
|
Area of largest
not found face (pixel x pixel) |
225 |
240 |
0 |
0 |
1276 |
|
Area of the
largest face (pixel x pixel) |
1840 |
266 |
87292 |
0 |
2279 |
|
Area of the
image (pixel x pixel) |
835520 |
612480 |
784215 |
613440 |
801907 |
|
Largest not
found face to whole image ratio (%) |
0.027 |
0.039 |
0 |
0 |
0.159 |
|
Largest face to
whole image ratio (%) |
0.220 |
0.043 |
11.131 |
0 |
0.284 |
Table 1. The
results of our full experiment.
From Table 1 it shows that the experiment did not
perform well when the size of the faces in the image were lower than 0.16% of
the image. We can attribute that to the large radius size of the median filter
used in the different stages. Since the largest face that was not found had a
width of 22 pixels, it can be seen that having a blur radius of 13 pixels in
the last stage is too high for those faces to be found. To solve the problem,
we are exploring different radius sizes, which would allow the workers to also
find relatively (with respect to the dimensions of the whole image) smaller
faces within the image. In image 3 ( shown in figure
6), the image with the largest faces, that the workers were able to find the
faces at the start of the experiment in stage 1.
In the five images that we have tested, it can be
seen from the results that the ones with higher contrast got a higher
percentage of faces found. Also, if a person’s skin color is closer to the
background color and the lighting conditions were not good, then the person
would blend into the background and become harder to locate.
Future Work
The complete framework will be tested with four
different experiments. The first experiment will contain all 5 stages shown
above and have 3 workers for each stage and their results will be aggregated
(i.e. the union of the three submissions) into a single image for the second
stage and so on. The second experiment will use the same five stages as above
but will only use the data from the first worker to submit the results for each
of the stages. So this experiment will test if one worker would be able to
perform equally to the three workers. The third experiment will use the same
data from the first experiment for the first stage, but instead of being sent
to stage two it will be sent to stage 3 directly, and after that is done the
results will go to the final (5th) stage, thus ending the experiment with a
total of three stages instead of the five from experiment one. The reasoning
behind this experiment is to find out whether this problem can be solved with
fewer steps while yielding the same results. The final experiment will be the
same as experiment 3 but will only use the information delivered by the first
workers to submit (similar to experiment 2).
With further revisions or clarifications to the
task interface (e.g. tell the worker that if they are unsure whether or not
there is a face in the region, to go ahead and cover it with a box, or put a
slider labeled “How confident are you that this is a face” next to each box),
we expect to greatly increase the accuracy of the crowd to detect faces or
other PII.
There will also be an addition of a face
detection algorithm to reduce the workload on the workers, as well as make the
workers focus on the faces that the face detection algorithm was not able to
find. The system will also include a method that would calculate the optimal
radii for all the stages.
Gross et al., introduces an algorithm that maintains both privacy and utility of images
by classifying an image after blurring out the areas of sensitive information.
This is valuable to the next step of our system: to show possible adaptors that
the system works within their required specifications.
Zerr
et al., estimated the degree of
privacy of images by the privacy assignments obtained through a social
annotation game. This can be integrated into our system to determine the radius
assigned to each image according to the degree of security.
If we present this fully evaluated algorithm as
an add-on to VizWiz or other
real-time crowd-powered
interfaces, we would need to greatly reduce the latency from the time the
image is initially posted to AMT to the time it is fully processed and
redacted, likely using
TurKit to facilitate the
automation.
Conclusion
In conclusion, our platform was able to redact
all the faces that covered more than 0.16% of the image. At the current stage
we are not considering our results to be acceptable. Due to the various ratios
of the faces in different images, our radius selection was increased in order
for us to hide the faces in image 3 (figure 6), which caused the smaller faces
in other images to be lost. This problem will be addressed in future work.
The current results show that this framework is a
viable product to solve the issue caused by the referenced papers.
References
1. Amazon Mechanical Turk. http://www.mturk.com/, 2010.
○ DOI: 10.1145/2047196.2047201
○ DOI: 10.1145/1866029.1866080
5. CrowdLib, http://www.cs.umd.edu/hcil/crowdlib/
○ DOI: 10.1109/ICCV.2009.5459413
9. Krishna, Ranjay, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen et al. "Visual genome: Connecting language and vision using crowdsourced dense image annotations." arXiv preprint arXiv:1602.07332 (2016).
○ DOI: 10.1145/2531602.2531733
○ DOI: 10.1145/1866029.1866040
13. Python Imaging Library (PIL) by PythonWare, http://www.pythonware.com/products/pil/
○ DOI: 10.1109/IROS.2010.5650464